
Scrapy(三)
现在,我们来写一个爬虫获取上交所和深交所所有股票的名称和交易信息,然后输出为文件。
原理分析
股票数据可以从百度股票查看,比如我们想查看乐视网股票,那我们就在搜索框中输入‘乐视网’然后回车即可看到乐视网股票信息。 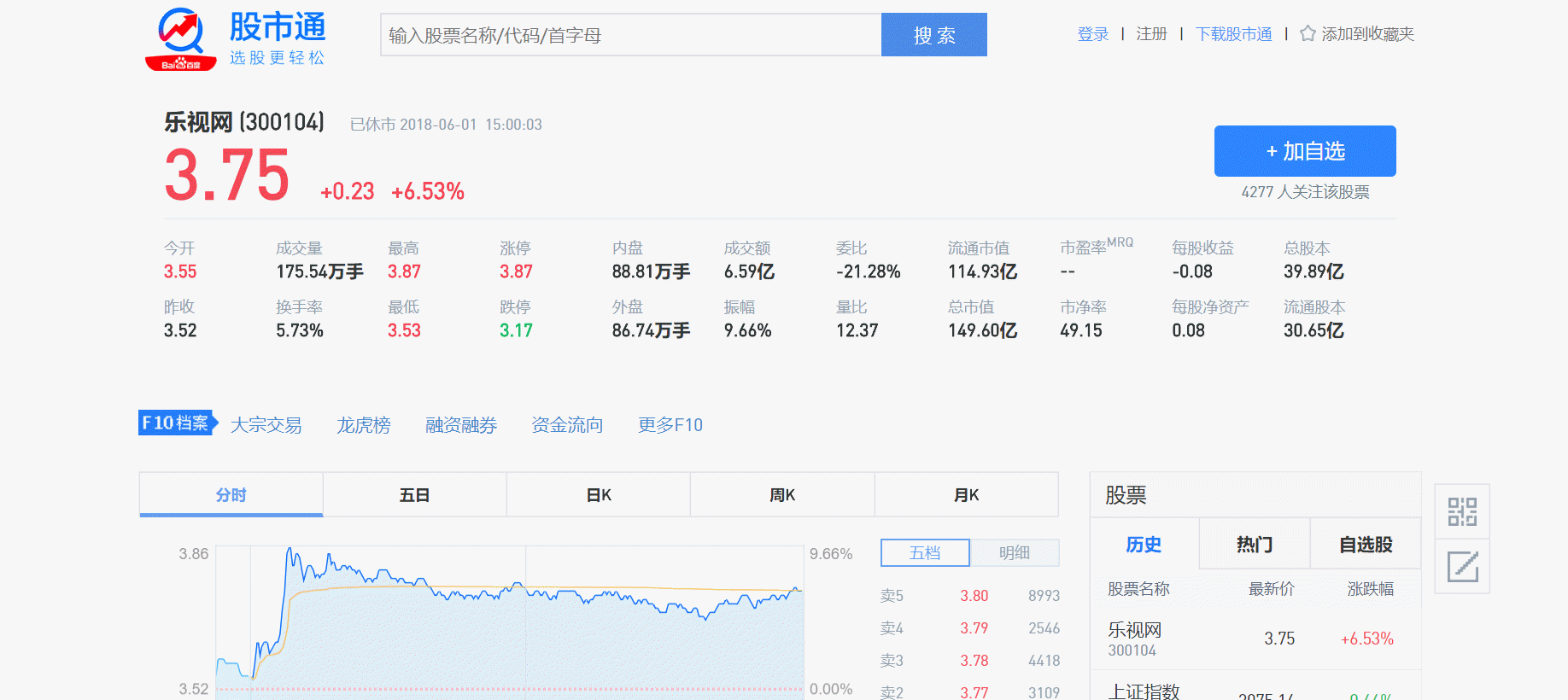
由于百度股票只有单个股票的信息,所以还需要当前股票市场中所有股票的列表,在这里我们选择东方财富网,界面如下图所示 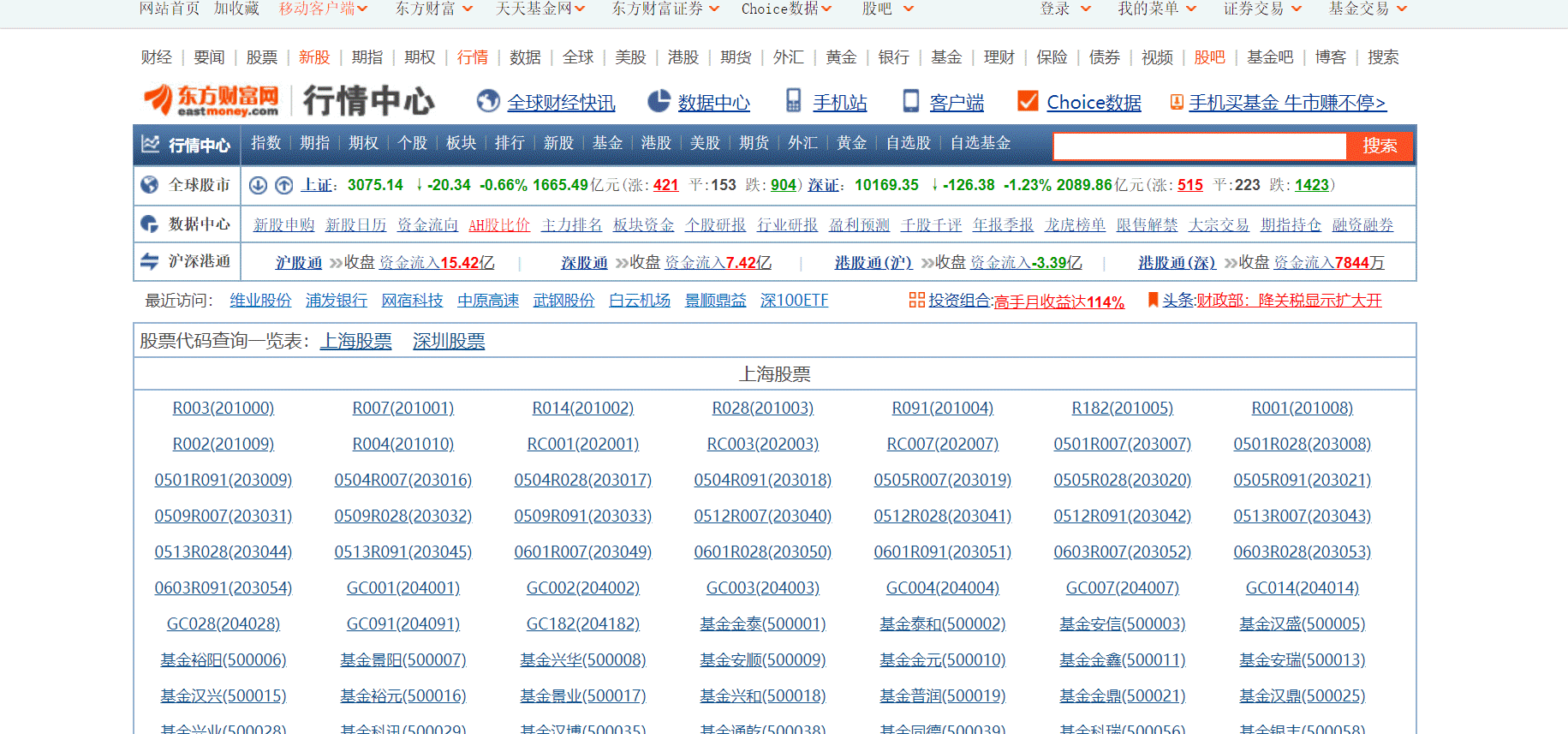
查看百度股票每只股票的网址:https://gupiao.baidu.com/stock/sz300023.html,可以发现网址中有一个编号300023正好是这只股票的编号,sz表示的深圳交易所。因此我们构造的程序结构如下:
- 步骤1: 从东方财富网获取股票列表;
- 步骤2: 逐一获取股票代码,并增加到百度股票的链接中,最后对这些链接进行逐个的访问获得股票的信息;
- 步骤3: 将结果存储到文件。
接着查看百度个股信息网页的源代码,发现每只股票的信息在html代码中的存储方式。了解清楚股票信息是为了方便提取,现在我们可以编写代码了。
新建一个scrapy项目,在spiders包下新建stocks_spider.py文件,这就是我们要写的爬虫。里面代码如下:
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['http://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key] = val
infoDict.update(
{'股票名称': re.findall('\s.*\(', name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict
在pipelines.py我们定义一个处理股票数据的类:
# 每个pipelines类中有三个方法
class StocksInfoPipeLine(object):
# 当一个爬虫被调用时,对应的pipeline启动的方法
def open_spider(self, spider):
self.fp = open('StockInfo.txt', 'w')
# 当一个爬虫关闭或者结束时,对应的pipelines结束的方法
def close_spider(self, spider):
self.fp.close()
# 对每一个Item项进行处理时所对应的方法,也是pipelines中最主体的函数
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.fp.write(line)
except:
pass
return item
在setting.py文件设置四处地方:
# 模拟浏览器访问
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
# 启用我们定义的pipeline类
ITEM_PIPELINES = {
'scrapy_demo.pipelines.StocksInfoPipeLine': 300
}
# 防止因网络原因下载不了
DOWNLOAD_DELAY = 5
# 防止403 HTTP status code is not handled or not allowed
HTTPERROR_ALLOWED_CODES = [403]
然后启动我们的爬虫。
scrapy crawl stocks
当我们一个爬虫项目量非常大时候,我们可能不能一次执行完毕,需要分好几次执行,这时候,我们只需要在启动爬虫的时候键入命令:
scrapy crawl xxx -s JOBDIR=job1
这时候我们可以看到任务开始执行了,当我们想要暂停的时候按下ctrl+c。当我们想要恢复的时候键入:
scrapy crawl xxx -s JOBDIR=job1