
Scrapy
Scrapy的特性
Scrapy 是一个分布式爬取框架。其特性有:
- HTML,XML源数据选择及提取的内置支持
- 提供了一系列在spider之间共享的可复用的过滤器(即Item Loaders),对智能处理爬取数据提供了内置支持
- 通过feed导出提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
- 提供了media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。
- 高扩展性。你可以通过使用signals,设计好的API(中间件,extensions,pipelines)来定制实现你的功能。
内置的中间件及扩展为下列功能提供了支持:
- cookies and session 处理
- HTTP 压缩
- HTTP 认证
- HTTP 缓存
- user-agent模拟
- robots.txt
- 爬取深度限制
- 健壮的编码支持和自动识别,用于处理外文、非标准和错误编码问题
- 针对多爬虫下性能评估、失败检测,提供了可扩展的 状态收集工具 。
- 内置 Web service, 使您可以监视及控制您的机器。
安装Scrapy
Scrapy 是单纯用 Python 语言编写的库。所以它有依赖一些第三方库,如lxml, twisted,pyOpenSSL等。我们也无需逐个安装依赖库,使用 pip 方式安装 Scrapy 即可。pip 会自动安装 Scrapy 所依赖的库。随便也说下 Scrapy 几个重要依赖库的作用。
- lxml:XML 和 HTML 文本解析器,配合 Xpath 能提取网页中的内容信息。
- Twisted:Twisted 是 Python 下面一个非常重要的基于事件驱动的IO引擎。
- pyOpenSSL:pyopenssl 是 Python 的 OpenSSL 接口。
如果我们想在anaconda上进行安装,打开Anaconda Command Prompt,在终端( 如果想装在本地可以直接在命令行提示符)输入以下命令进行安装:
pip install Scrapy
在安装过程中可能会出现Twisted安装错误,这时我们可以先下载Twisted到本地,然后执行以下命令安装:
pip install E:\xxx\xxx\Twisted-18.4.0-cp36-cp36m-win_amd64.whl
安装完成之后再执行pip install Scrapy即可安装成功
Scrapy项目
Scrapy新建项目需要通过命令行操作。在指定文件夹打开终端执行以下命令:
scrapy startproject 项目的名字
这里我们新建一个scrapy_demo,执行命令之后我们就得到一个scrapy项目,里面有如下内容:
scrapy_demo/
scrapy.cfg # deploy configuration file
scrapy_demo/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
说明一下这些文件作用:
- scrapy.cfg:项目的配置文件,开发无需用到。
- scrapy_demo:项目中会有两个同名的文件夹。最外层表示 project,里面那个目录代表 module(项目的核心)。
- scrapy_demo/items.py:以字段形式定义后期需要处理的数据。
- scrapy_demo/pipelines.py:提取出来的 Item 对象返回的数据并进行存储。
- scrapy_demo/settings.py:项目的设置文件。可以对爬虫进行自定义设置,比如选择深度优先爬取还是广度优先爬取,设置对每个IP的爬虫数,设置每个域名的爬虫数,设置爬虫延时,设置代理等等。
- scrapy_demo/spider: 这个目录存放爬虫程序代码。
- init.py:python 包要求,对 scrapy 作用不大。
第一个爬虫
我们来写一个简单的爬虫。在spiders文件夹下新建一个quotes_spider.py文件,我们输入内容:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
从以上代码我们可以看到,Spider子类继承父类scrapy.Spider;在Spider类里面定义了一些属性和方法:
- name:用于唯一标识Spider。在一个爬虫项目里它必须是唯一的,也就是说你不能有同名的爬虫。
- start_requests():必须返回一个可迭代的Requests对象(你可以返回一个requests列表或者一个生成器)。这些requests是用于启动爬虫时告知爬虫从哪里开始爬起。
- parse():一个用于处理返回爬取内容的方法,响应参数就是TextResponse(保存页面内容并有很多处理的方法)类型的。parse() 方法通常解析响应,将数据提取为字典,找到响应内容里的URL并创建新的请求。
启动爬虫
为了让我们的爬虫启动起来,我们在终端中改变当前路径到项目文件位置,然后输入:
scrapy crawl quotes
上面命令启动一个名字为quotes的爬虫,也就是我们刚刚添加的爬虫。该爬虫发送一下请求到quotes.toscrape.com。我们可以在终端看到如下输出:
...
2018-05-27 19:42:55 [scrapy.core.engine] INFO: Spider opened
2018-05-27 19:42:55 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-05-27 19:42:55 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-05-27 19:42:56 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2018-05-27 19:42:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/2/> (referer: None)
2018-05-27 19:42:57 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/2/>
...
这时候我们就可以在当前文件夹看到生成的quotes-1.html和quotes-2.html。这就是我们爬取下来的内容。
Scrapy架构
学习Scrapy,想一下子就熟悉它,这几乎是不太可能的。我们应该按照一定的顺序层次逐步深入学习:先整体再局部。下图是Scrapy的架构图,它能让我们对Scrapy有了大体的认识。 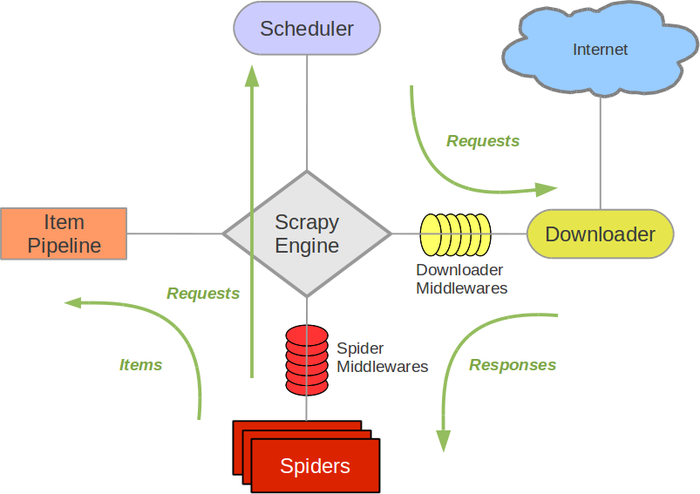 各个组件的作用:
各个组件的作用:
- Scheduler:调度器。负责接受 Engine 发送过来的 Requests 请求,并将其队列化;
- Item Pipeline:Item Pipeline负责处理被spider提取出来的item。其有典型应用,如清理 HTML 数据、验证爬取的数据(检查 item 包含某些字段)、查重(并丢弃)、爬取数据持久化(存入数据库、写入文件等);
- Scrapy Engine:引擎是 Scrapy 的中枢。它负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件;
- Downloader Middlewares:下载中间件是 Engine 和 Downloader 的枢纽。负责处理 Downloader 传递给 Engine 的 responses;它还支持自定义扩展。
- Downloader:负责下载 Engine 发送的所有 Requests 请求,并将其获取到的 responses 回传给 Scrapy Engine;
- Spider middlewares:Spider 中间件是 Engine 和 Spider 的连接桥梁;它支持自定义扩展来处理 Spider 的输入(responses) 以及输出 item 和 requests 给 Engine ;
- Spiders:负责解析 Responses 并提取 Item 字段需要的数据,再将需要跟进的URL提交给引擎,再次进入Scheduler(调度器);
Scrapy工作机制
我们对 Scrapy 有了大体上的认识。接下来我们了解下 Scrapy 内部的工作流程。同样先放出一张图,然后我再细细讲解。 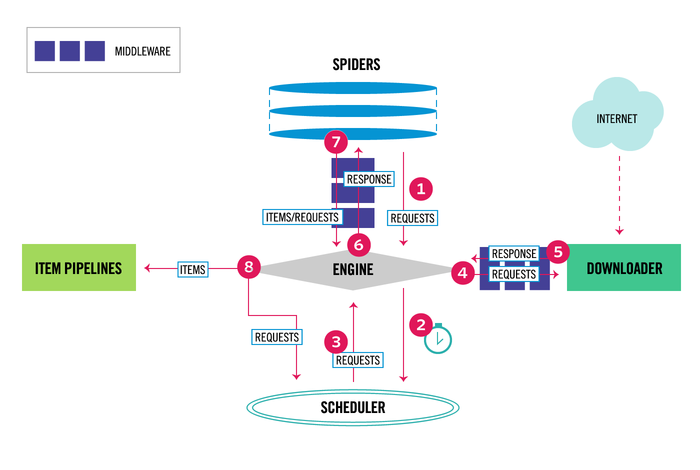
- 当引擎(Engine) 收到 Spider 发送过来的 url 主入口地址(其实是一个 Request 对象, 因为 Scrapy 内部是用到 Requests 请求库),Engine 会进行初始化操作。
- Engine 请求调度器(Scheduler),让 Scheduler 调度出下一个 url 给 Engine。
- Scheduler 返回下一个 url 给 Engine。
- Engine 将 url通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,Downloader 生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给 Engine。
- 引擎将从下载器中接收到 Response 发送给Spider处理。
- Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给引擎。
- Engine 将 Spider 返回的爬取到的 Item 转发给Item Pipeline,顺便也将 Request 给调度器。
- 重复(第2步)直到调度器中没有更多地request,引擎关闭该网站。