
Pandas
Pandas是基于NumPy构建的一个非常常用也非常好用的库,正如名字一样,国宝嘛是很受欢迎的!它含有使数据分析工作变得更快更简单的高级数据结构和操作工具。
基本数据结构
Pandas有两种自己独有的基本数据结构。不过我们要知道的是,pandas它固然有着两种数据结构,因为它依然是Python的一个库,所以Python中有的数据类型在这里依然适用,也同样还可以使用类来自定义数据类型。只不过Pandas里面定义的两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
在使用Pandas的代码中,我们一般使用下面这样的pandas引入约定:
from pandas import Series, DateFrame
import pandas as pd
因此,只要你在代码中看到’pd.’,就得想到这是pandas。因为Series和DataFrame使用的次数非常多,所以将其引入命名空间会更加方便。
Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series: 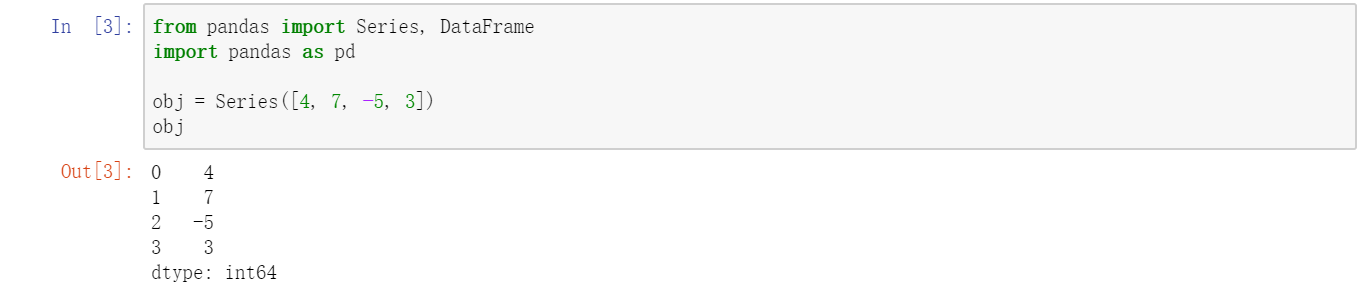 Series的字符串表现形式为:索引在左边,值在右边(其实我们可以理解为立着的list)。由于我们没有为数据指定索引,于是会自动创建一个0到N1(N为数据的长度)的整数型索引。你可以通过Series 的values和index属性获取其数组表示形式和索引对象:
Series的字符串表现形式为:索引在左边,值在右边(其实我们可以理解为立着的list)。由于我们没有为数据指定索引,于是会自动创建一个0到N1(N为数据的长度)的整数型索引。你可以通过Series 的values和index属性获取其数组表示形式和索引对象:  通常,我们希望所创建的Series带有一个可以对各个数据点进行标记的索引:
通常,我们希望所创建的Series带有一个可以对各个数据点进行标记的索引: 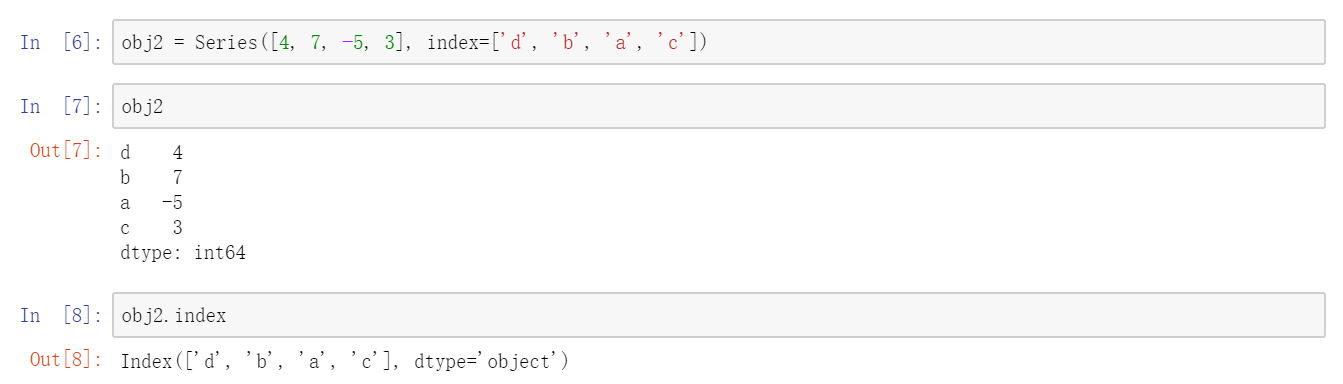 与普通NumPy数组相比,你可以通过索引的方式选取和修改Series中的单个或一组值:
与普通NumPy数组相比,你可以通过索引的方式选取和修改Series中的单个或一组值: 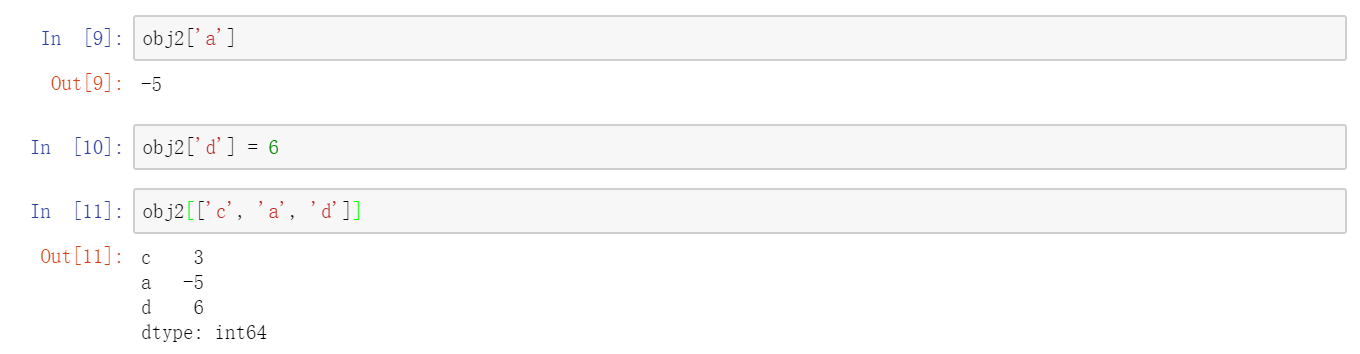 到这里是不是感觉有点像字典?没错,它确实是一个字典。我们来看下面定义:
到这里是不是感觉有点像字典?没错,它确实是一个字典。我们来看下面定义:  这时候,我们依然可以自定义索引。Pandas的优势在这里体现出来,如果自定义了索引,自定的索引会自动匹配原来的索引,如果匹配成功,就取原来索引对应的值,这个可以简称为“自动对齐”。
这时候,我们依然可以自定义索引。Pandas的优势在这里体现出来,如果自定义了索引,自定的索引会自动匹配原来的索引,如果匹配成功,就取原来索引对应的值,这个可以简称为“自动对齐”。  这里“Java”没有对应的值与之匹配,所以其结果就为NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值)。pandas的isnull和notnull函数可用于检测缺失数据:
这里“Java”没有对应的值与之匹配,所以其结果就为NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值)。pandas的isnull和notnull函数可用于检测缺失数据: 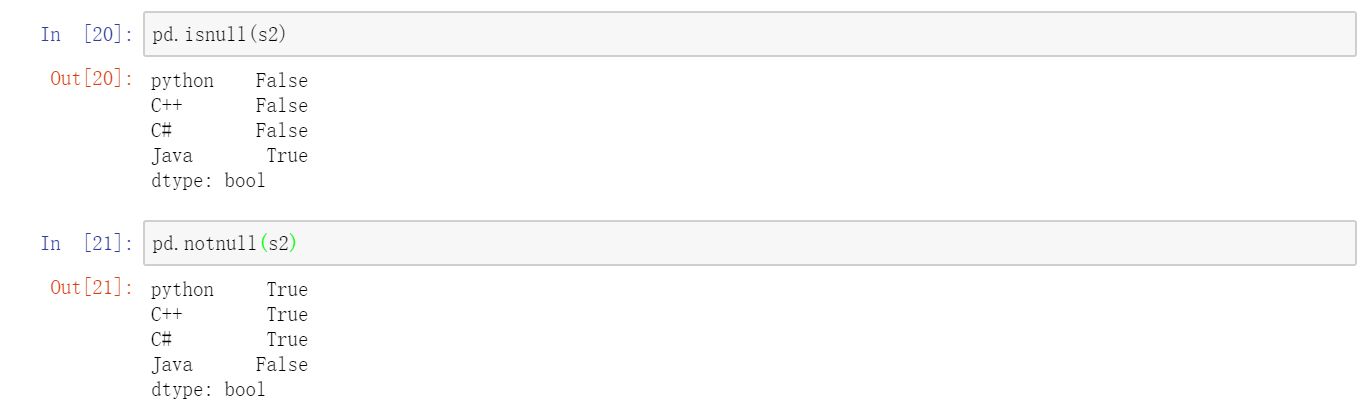 Series也有类似的实例方法:
Series也有类似的实例方法: 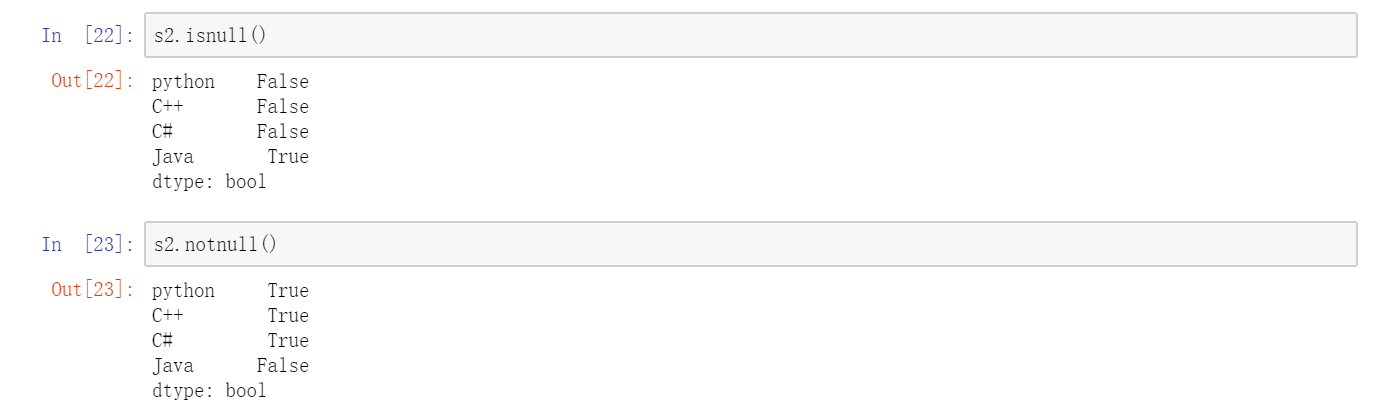 对于许多应用而言,Series最重要的一个功能是:它在算术运算中会自动对齐不同索引的数据。
对于许多应用而言,Series最重要的一个功能是:它在算术运算中会自动对齐不同索引的数据。 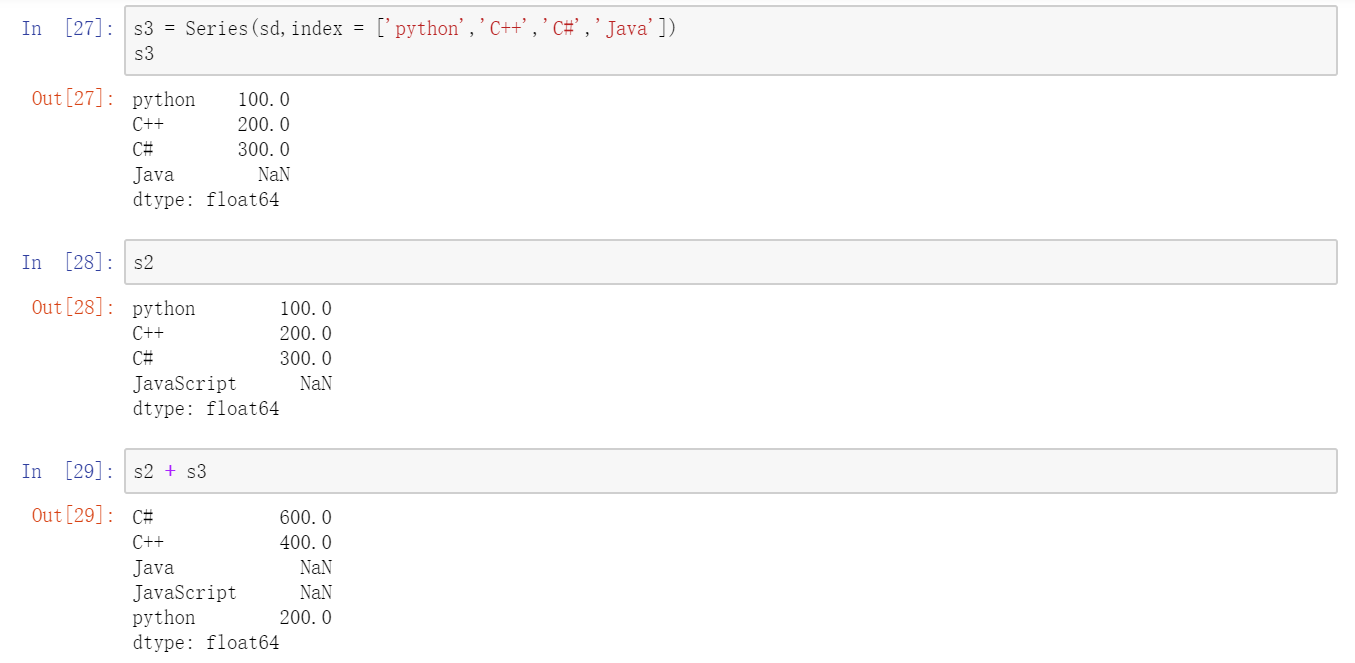
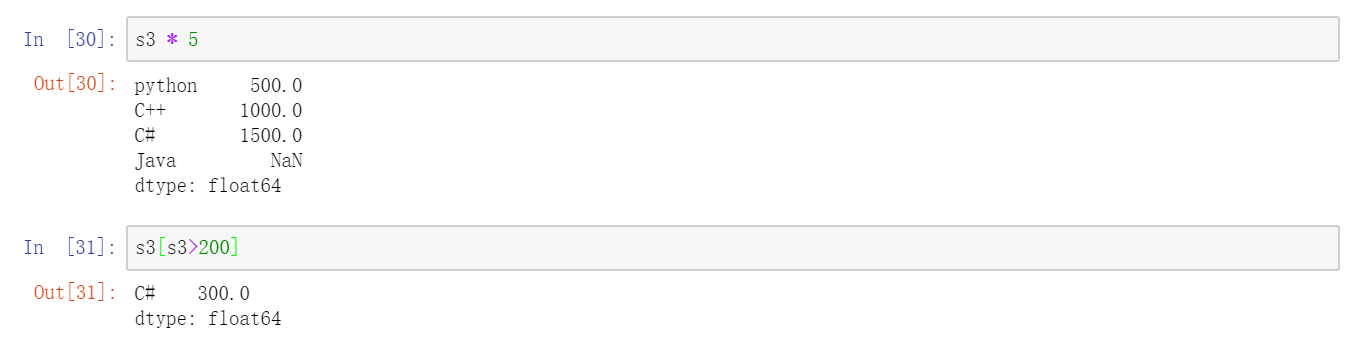 Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切: 
DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。它非常近似一个电子表格。
构建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典: 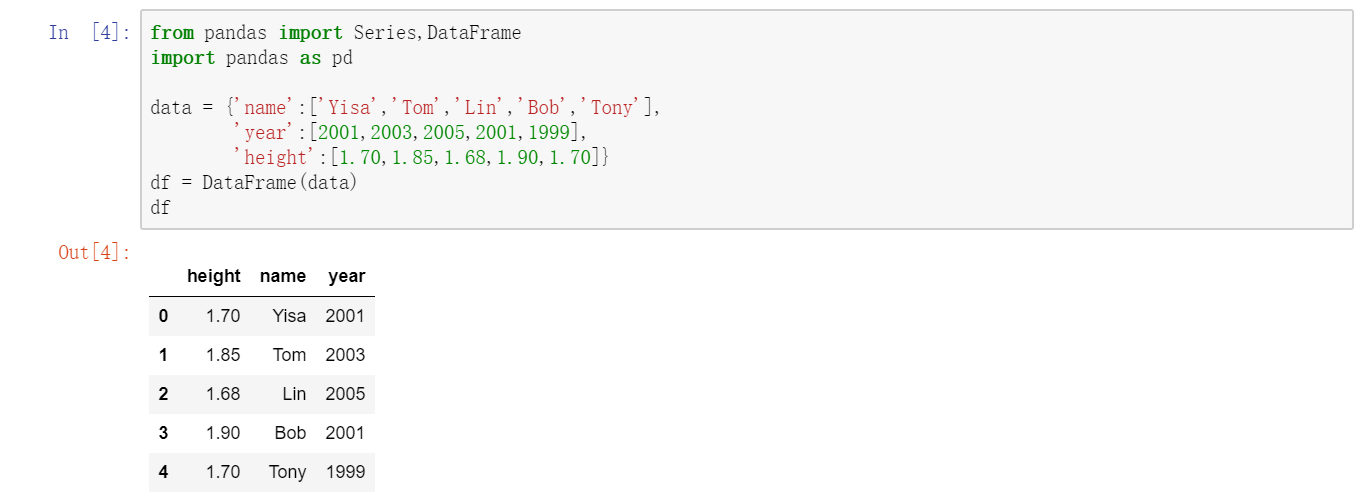 如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列: 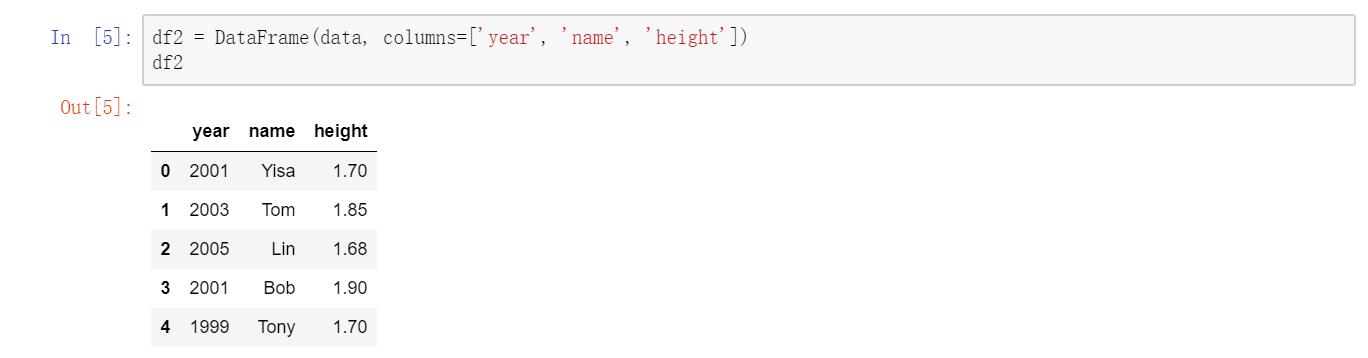 跟Series一样,如果传入的列在数据中找不到,就会产生NAN值:
跟Series一样,如果传入的列在数据中找不到,就会产生NAN值: 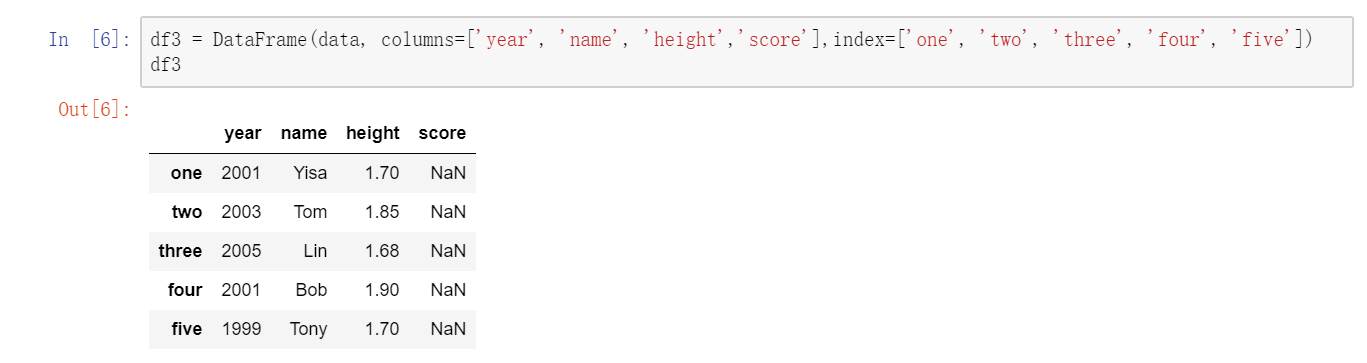 通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,也就是说DataFrame的一列其实就是一个Series:
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,也就是说DataFrame的一列其实就是一个Series: 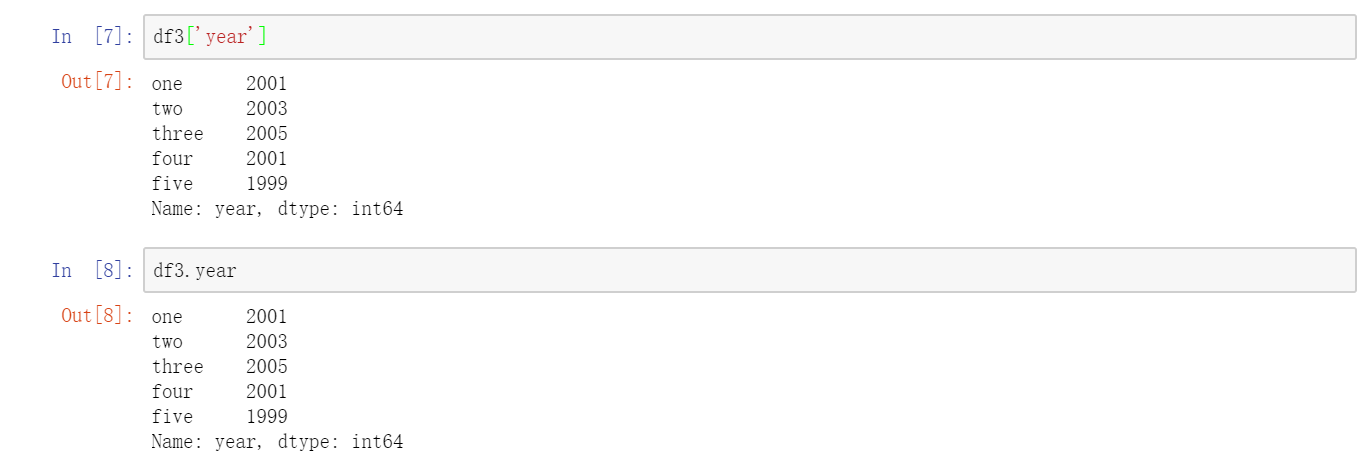 注意,返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应地设置好了。当然,行也可以通过位置或名称的方式进行获取,例如用索引字段ix:
注意,返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应地设置好了。当然,行也可以通过位置或名称的方式进行获取,例如用索引字段ix:  列可以通过赋值的方式进行修改。例如,我们可以给那个空的”score”列赋上一个标量值或一组值:
列可以通过赋值的方式进行修改。例如,我们可以给那个空的”score”列赋上一个标量值或一组值: 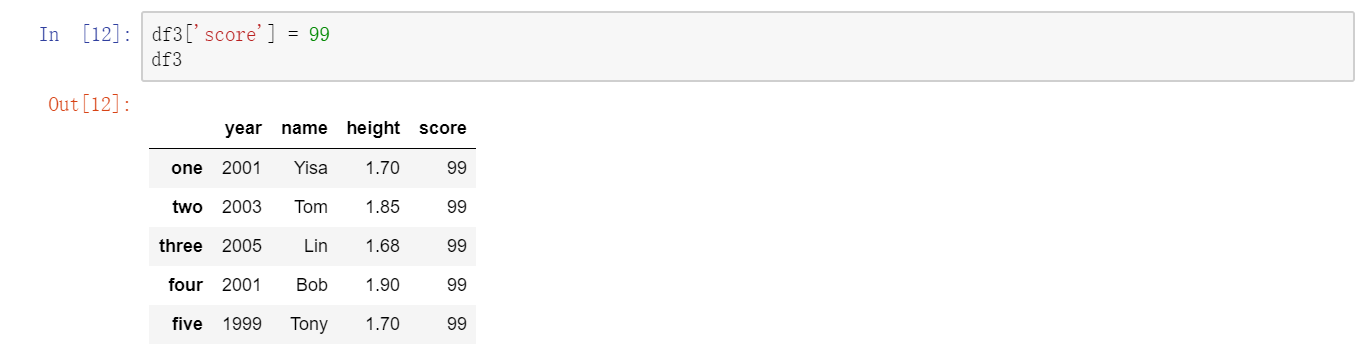 将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值:
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值: 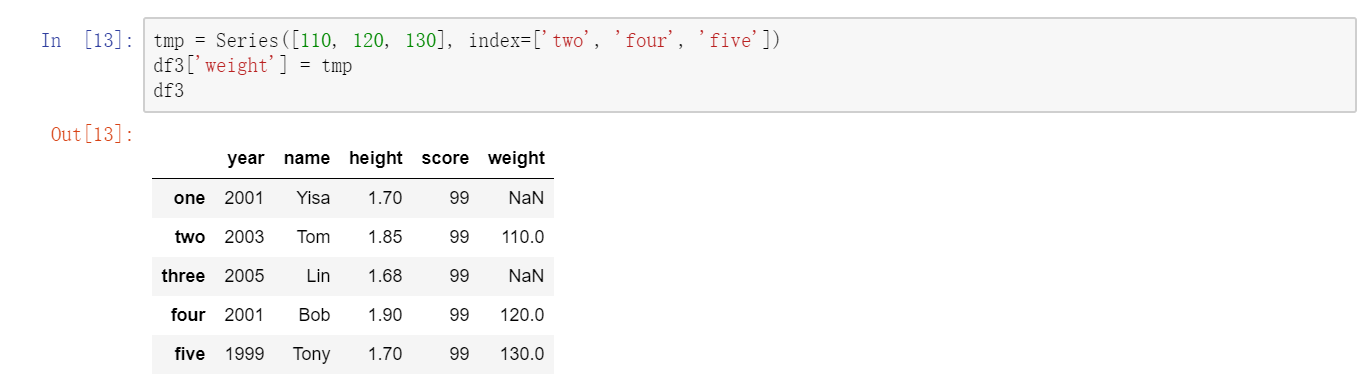 关键字del用于删除列:
关键字del用于删除列: 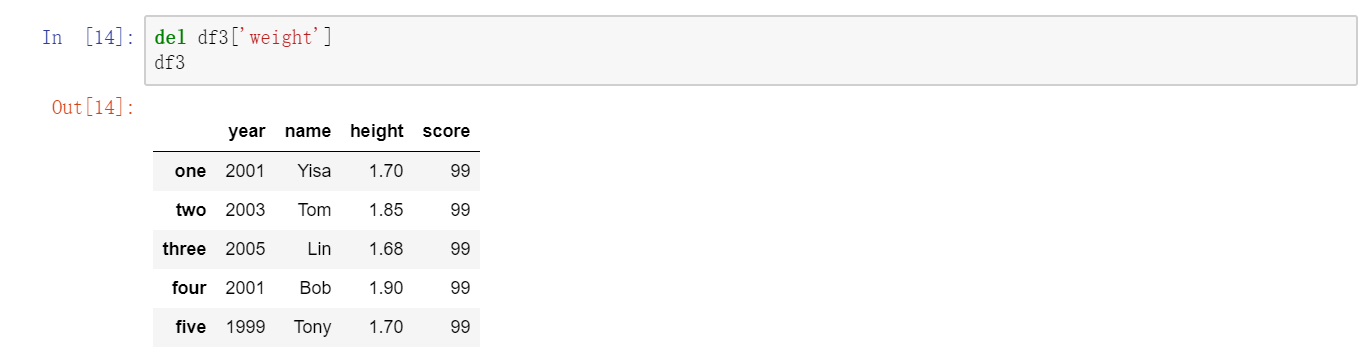 另一种常见的数据形式是嵌套字典(也就是字典的字典),它也可以用来构建DataFrame,如果将它传给DataFrame,它就会被解释为:外层字典的键作为列,内层键则作为行索引:
另一种常见的数据形式是嵌套字典(也就是字典的字典),它也可以用来构建DataFrame,如果将它传给DataFrame,它就会被解释为:外层字典的键作为列,内层键则作为行索引: 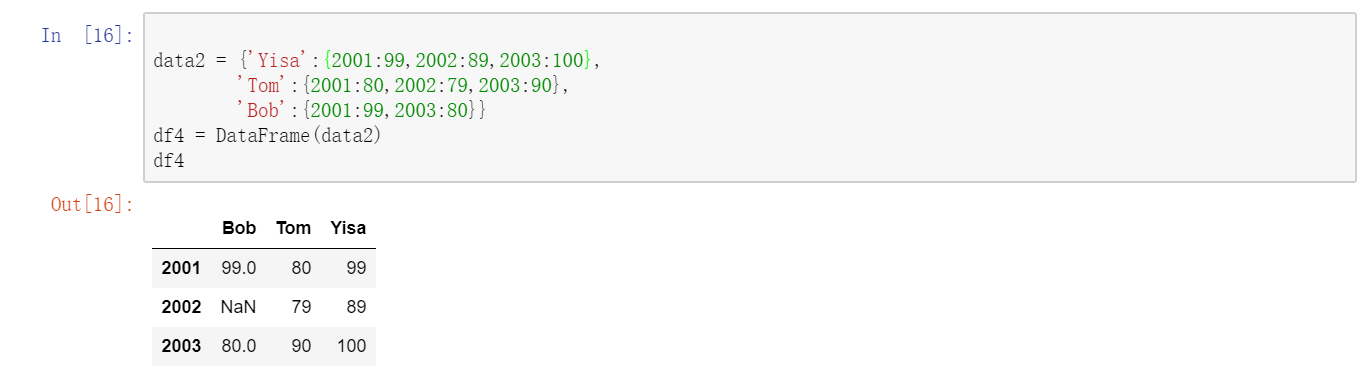 下面列出了DataFrame构造函数所能接受的各种数据。
下面列出了DataFrame构造函数所能接受的各种数据。
| 类型 | 说明 |
|---|---|
| 二维ndarray | 数据矩阵,还可以传入行标和列表 |
| 由数组、列表或元组组成的字典 | 每个序列会变成DataFrame的一列,所有序列的长度必须相同 |
| NumPy的结构化/记录数组 | 类似于“由数组组成的字典” |
| 由Series组成的字典 | 每个Series会成为一列,如果没有显式指定索引,则各Series的索引会被合并成结果的行索引 |
| 字典或Series的列表 | 各内层字典会成为一列,键会被合并成结果的行索引,跟“由Series组成的字典”的情况一样 |
| 字典或Series的列表 | 各项将会成为DataFrame的一行,字典键或Series索引的并集将会成为DataFrame的列标 |
| 由列表或元组组成的列表 | 类似于“二维ndarray” |
| 其它DataFrame | 该DataFrame的索引将会被沿用,除非显式指定了其他索引 |
| Numpy的MaskedArray | 类似于“二维ndarray”的情况,只是掩码值在结果DataFrame会成NAN/缺失值 |