
模块与包
模块和包都是Python组织代码的方式。假想一下,你写一个程序,写了一万行,都在一个.py文件,那么你阅读起来是不是很费劲,如果中间出现bug调试也会很困难。那如果有一天让别人来读你的代码,很难说别人不会有掐死你的冲动!
这个时候呢,我们就要考虑编写可维护的代码,我们可以把一个任务分成多个小任务,把一个函数拆分成多个函数,把函数安装一定的规则进行分组,分别放到不同文件里面,这样的话,每个.py文件包含的代码就好比较少,可读性和可维护性都比较好。
模块(Module)
在Python里面,一个.py文件就称之为一个模块(module).
使用模块的好处是:1、提高代码的可维护性。因为模块中放的就是经过分组的函数或者对象,且一个模块代码量不会太。2、提高代码的可复用性。写代码不必从零开始,当你写完一个模块,就可以被其他地方引用,比如我们写程序时常常用到其他模块,包括Python内置的模块和来自第三方的模块。3、可以避免函数名和变量名冲突。相同名字的函数和变量分别存放在不同模块中,这样我们自己编写模块时就不用考虑定义的名字与其他模块冲突。不过要注意不与内置函数名字冲突。
标准库模块
python本身内置了很多非常有用的模块,只要安装Python,就可以使用这些模块。 我们可以在Python的安装目录xia找到Lib目录,这里面都是Python内置模块,也称标准库模块。  或者运行python3.6 manuals,启动服务器,然后在浏览器输入http://localhost:64684/进行查看:
或者运行python3.6 manuals,启动服务器,然后在浏览器输入http://localhost:64684/进行查看: 
自定义模块
自定义模块又可以分为第三方模块和自己编写的模块。下面我们来编写一个arcadd模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Bowen Zou'
import sys
def add():
args = sys.argv
if len(args) == 1:
print('请输入一个或多个数字!')
elif len(args) >= 2:
sum = 0
for i in range(1, len(args)):
sum += int(args[i])
print(sum)
else:
print("未知错误!")
if __name__ == '__main__':
add()
第一行和第二行什么意思第一节课就已经有说过了,如果忘记请回去查找;第四行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;第六行使用__author__变量把作者写进去,这样别人可以瞻仰你的大名。
以上就是Python模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
使用sys模块的第一步,就是导入该模块:
import sys
sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称。
最后,注意到这两行代码:
if __name__=='__main__':
add()
当我们在命令行运行arcadd模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
作用域
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在Python中,是通过_前缀来实现的。
公开的函数和变量名可以被直接引用,比如:abc,PI,sum等
形如__xxx__这样的变量是特殊变量,可以被直接,但是又特殊用途,比如上面的__author__,__name__就是特殊变量
形如_xxx和__xxx这样的函数或变量就是私有的,不应该被直接引用,比如_abc,__abc等;之所以我们说,私有函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
包(package)
如果不同的人编写的模块相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子:如果我们编写一个处理时间格式的date.py文件,而这个名字叫date的模块和其他模块冲突了,那怎么办呢?这时我们就可以通过包来组织模块,避免冲突。定义一个包的方法是选择一个顶层包名,比如arcbasic,按照如下目录存放:
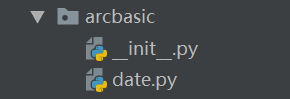
引入包以后,只要顶层包名不与别冲突,那所有的模块都不会与别人冲突。现在,date.py模块的名字就变成arcbasic.date了。
请注意,每一个包下面都会有一个名为__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当初普通目录,而不是一个包。init.py可以是空文件,也可以含有Python代码,因为__init__.py本身就是一个模块,而它的模块名等于包名,也就是arcbasic。
包是可以多层嵌套的,也就是可以有多级目录,组成多级层次的包结构。
库(library)
Python库是参考其他编程语言的说法,就是指python中一定功能的代码集合,用其他人使用的代码组合。在python中是包和模块的形式。lib其实只是一个抽象概念。
模块的安装和使用
Python本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。
安装
在Python中,安装第三方模块,是通过包管理工具pip完成的。
pip install Pillow
在使用Python时,我们经常需要用到很多第三方库,例如,上面提到的Pillow,以及之后我们要学的科学计算Numpy、数据处理pandas、可视化工具matplotlib、网络爬虫Urllib等等。用pip一个一个安装费时费力,还需要考虑兼容性。我们推荐直接使用Anaconda,这是一个基于Python的数据处理和科学计算平台,它已经内置了许多非常有用的第三方库,我们装上Anaconda,就相当于把数十个第三方模块自动安装好了,非常简单易用。请猛戳:安装anaconda的方法
使用
1、import
导入模块我们使用关键字 import。import 的语法基本如下:
import module1[, module2[,... moduleN]
比如我们使用标准库模块中的 math 模块。当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
import math
print(math.pi)
注意:一个模块只会被导入一次,不管你执行了多少次 import。这样可以防止导入模块被一遍又一遍地执行。
2、from···import
我们想直接导入某个模块中的某一个功能,也就是属性和方法的话,我们可以使用 from···import 语句。
from modname import name1[, name2[, ... nameN]]
你一定想知道,from···import和import方法有啥区别呢?好吧我们先看两个例子
import sys
print(sys.path) # python 解释器就依次从这些目录中去寻找所引入的模块
from···import 直接导入 path 属性
from sys import path
print(sys.path)
3、from ··· import *
这个语句可以把某个模块中的所有方法属性都导入。
from sys import *
print(version)
print(executable)
print(path)