
浏览器的工作原理
前端是指网页页面,包括控件布局,字体,配色,事件等。前端是在浏览器中展现,本篇我们就来讲讲浏览器的工作原理,包括浏览器渲染、浏览器队列事件、浏览器缓存、浏览器存储。
浏览器渲染
浏览器渲染页面的过程,从耗时的角度来说,浏览器请求,加载,渲染一个页面,主要经历一下过程:
- DNS查询
- TCP连接
- HTTP请求
- 服务器响应
- 客户端渲染
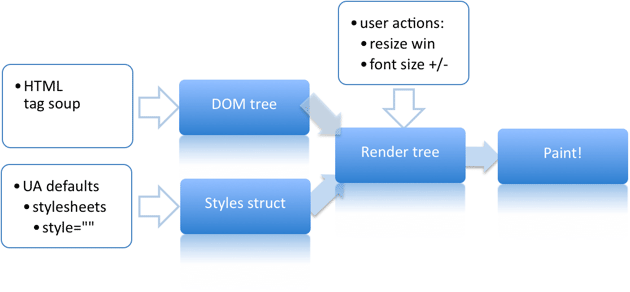
这里讲浏览器对内容的渲染,也即是客户端渲染,这一部分又可以分为以下五步:
- 处理HTML标记构建DOM树
- 处理CSS标记并构建CSSOM树
- 将DOM与CSSOM合并成一个渲染树。比如像 <head> 标签内容或带有 display: none; 的元素节点并不包括在 Rendering Tree 中 。
- 根据渲染树进行布局,主要是定位坐标和大小,是否换行,以及 position、overflow、z-index 等属性,这个过程称为 Flow 或 Layout 。
- 将各个节点绘制到屏幕上。
注意:CSS匹配HTML元素是一个相当复杂和有性能问题的事情。所以,你就会在N多地方看到很多人都告诉你,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去,······
需要明白,这五个步骤并不一定一次性顺序完成。如果DOM或者CSSOM被修改,以上过程需要重复执行,这样才能计算出哪些像素需要在屏幕上进行重新渲染。此过程称为 Repaint 或 Reflow。
Repaint——屏幕的一部分要重画。比如某个CSS的背景色变了,但是元素的几何尺寸或相对位置没有变,浏览器仅仅会应用新的样式重绘此元素,此过程称为Repaint。
Reflow——当元素改变的时候,将会影响文档内容或结构,或元素位置,此过程称为Reflow。HTML 使用的是flow based layout,也就是流式布局,所以如果某元素的几何尺寸或相对位置发生了变化,需要重新布局,也就Reflow。
Reflow的成本比Repaint的成本高得多的多。DOM Tree里的每个结点都会有reflow方法,一个结点的reflow很有可能导致子结点,甚至父点以及同级结点的reflow。在一些高性能的电脑上也许还没什么,但是如果reflow发生在手机上,那么这个过程是非常痛苦和耗电的。 ——浏览器的渲染原理简介
很明显,任何改变或影响元素几何尺寸或者相对位置的行为都会导致产生Reflow,比如:
- 增加、删除、或改变 DOM 节点
- 增加、删除 ‘class’ 属性值
- 元素尺寸改变
- 文本内容改变
- 浏览器窗口改变大小或拖动
- 动画效果进行计算和改变 CSS 属性值
- 伪类激活(:hover) –前端工程师需要明白的「浏览器渲染」
那么如何减少reflow或者repaint呢,当然是减少做出产生repaint/reflow的行为了。
阻塞渲染:CSS与JavaScript——谈论资源的阻塞时,我们要清楚:现代浏览器总是并行加载资源。例如,当 HTML 解析器(HTML Parser)被脚本阻塞时,解析器虽然会停止构建 DOM,但仍会识别该脚本后面的资源,并进行预加载。
- 默认情况下,CSS 被视为阻塞渲染的资源,这意味着浏览器将不会渲染任何已处理的内容(CSSOM 构建时,JavaScript 执行和DOM 构建将暂停),直至 CSSOM 构建完毕。
- JavaScript 不仅可以读取和修改 DOM 属性,还可以读取和修改 CSSOM 属性。
- 当浏览器遇到一个 script 标记时,DOM 构建将暂停,直至脚本完成执行。
所以,script 标签的位置很重要。实际使用时,可以遵循下面两个原则:
- CSS 优先:引入顺序上,CSS 资源先于 JavaScript 资源。
- JavaScript 应尽量少影响 DOM 的构建。
如果了解清楚浏览器的渲染过程、渲染原理,其实就掌握了指导原则。根据优化原则,可以实现出无数种具体的优化方案,各种预编译、预加载、资源合并、按需加载方案都是针对浏览器渲染习惯的优化。
浏览器事件
众所周知JavaScript是基于单线程运行的,同时又是可以异步执行的,一般来说这种既是单线程又是异步的语言都是基于事件来驱动的,恰好浏览器就给JavaScript提供了这么一个环境。一般来说浏览器会有以下几个线程:
- js引擎线程(解释执行js代码、用户输入、网络请求)
- GUI线程(绘制用户界面、与js主线程是互斥的)
- http网络请求线程(处理用户的get、post等请求,等返回结果后将回调函数推入任务队列)
- 定时触发器线程(setTimeout、setInterval等待时间结束后把执行函数推入任务队列中)
- 浏览器事件处理线程(将click、mouse等交互事件发生后将这些事件放入事件队列中)
JavaScript函数的执行栈及回调:
function test1(){
test2()
console.log('大家好,我是test1')
}
function test2(){
console.log('大家好,我是test2')
}
function main(){
console.log('大家好,我是main')
setTimeout(()=>{
console.log('大家好,我是setTimeout')
},0)
test1()
}
main()
执行结果如下:
大家好,我是main
大家好,我是test2
大家好,我是test1
大家好,我是setTimeout
当我们调用一个函数,它的地址、参数、局部变量都会压入到一个 stack 中
- step1:main()函数首先被调用,进入执行栈打印‘大家好,我是main’
- step2:遇到setTimeout,将回调函数放入任务队列中
- step3:main调用test1,test1函数进入stack中将被执行
- step4:test1执行,test1调用test2
- step5:test2执行,打印‘大家好,我是test2’
- step6:test2执行完毕从stack弹出回到test1,打印‘大家好,我是test1’
- step6:主线程执行完毕,进入callback queue队列执行setTimeout的回调函数打印‘大家好,我是setTimeout’ 至此整个程序执行完毕,不过event loop一直在等待着其他的回调函数。
用代码表示的话大概是这样:
while(queue.waitForMessage()){
queue.processNextMessage()
}
这个线程会一直在等待其他回调函数过来例如click、load、setTimeout等
macrotask 与 microtask
接下来看段代码想想这个的运行结果是怎样的:
setTimeout1 = setTimeout(function(){
console.log('---1---')
},
0
)
setTimeout2 = setTimeout(function(){
Promise.resolve().then(() =>{
console.log('---2---')
})
console.log('---3---')
},
0
)
new Promise(function(resolve){
console.time("Promise")
for(var i = 0;i < 1000000;i++){
i === (1000000-1) && resolve()
}
console.timeEnd("Promise")
}).then(function(){
console.log('---4---')
});
console.log('---5---')
microtasks包括:
- process.nextTick 将某个任务放到下一个Tick中执行,简单讲就是延迟执行。
- promise 抽象异步处理对象以及对其进行各种操作的组件。
- Object.observe 用于异步地观察对象的更改(现在浏览器基本已经不在使用)
- MutationObserver 在某个范围内的DOM树发生变化时作出适当反应
macrotasks包括:
- setTimeout
- setInterval
- setImmediate
- I/O
- UI渲染
据whatwg规范介绍:
- 一个事件循环(event loop)会有一个或多个任务队列(task queue)
- 每一个 event loop 都有一个 microtask queue
- task queue == macrotask queue != microtask queue
- 一个任务 task 可以放入 macrotask queue 也可以放入 microtask queue 中
- 调用栈清空(只剩全局),然后执行所有的microtask。当所有可执行的microtask执行完毕之后。循环再次从macrotask开始,找到其中一个任务队列执行完毕,然后再执行所有的microtask,这样一直循环下去
so,正确的执行步骤应该为:
step1:执行脚本,把这段脚本压入task queue,此时
stacks:[]
task queue:[script]
microtask queue:[]
step2:遇到setTimeout1,setTimeout可当作一个task,所以此时
stacks:[script]
task queue:[setTimeout1]
microtask queue:[]
step3:继续往下执行,遇到setTimeout2,将setTimeout2压入task queue中
stacks:[script]
task queue:[setTimeout1,setTimeout2]
microtask queue:[]
step4:继续往下执行,new Promise,按同步流程往下走,输出new Promise内的执行时间
stacks:[script]
task queue:[setTimeout1,setTimeout2]
microtask queue:[]
step5:在i = 99999的时候,resolve()发生,把回调成功的代码段压入microtask queue,此时
stacks:[script]
task queue:[setTimeout1,setTimeout2]
microtask queue:[console.log('---4---')]
step6:继续往下执行就是console.log(‘—5—’),此时stacks队列里头的任务结束
stacks:[]
task queue:[setTimeout1,setTimeout2]
microtask queue:[console.log('---4---')]
step7:stacks队列为空,此时事件轮询线程会将microtask queue队列里头的任务推入stacks中去,然后执行输出’—4—‘
stacks:[]
task queue:[setTimeout1,setTimeout2]
microtask queue:[]
step8:stacks队列又为空了且microtask queue队列也是空着的,这时就会开始执行task queue里头的任务了,首先是setTimeout1,输出’—1—‘
stacks:[setTimeout1,setTimeout2]
task queue:[]
microtask queue:[]
step9:接着setTimeout2在里头遇到个Promise.resolve(),将回调成功的函数压入microtask queue队列里头,然后输出’—3—‘
stacks:[setTimeout2]
task queue:[]
microtask queue:[Promise.resolve()]
step10:当setTimeout2执行完毕之后执行microtask queue,输出’—2—‘,至此该代码段执行完毕
stacks:[]
task queue:[]
microtask queue:[]
用一句话简单的来说:整个的js代码macrotask先执行,同步代码执行完后有microtask执行microtask,没有microtask执行下一个macrotask,如此往复循环至结束
注:本节内容主要转载自文章《浏览器内的事件队列》
浏览器缓存
浏览器缓存,也就是客户端缓存,既是网页性能优化里面静态资源相关优化的一大利器,也是无数web开发人员在工作过程不可避免的一大问题,所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度。
它分为强缓存和协商缓存:
1)浏览器在加载资源时,先根据这个资源的一些http header判断它是否命中强缓存,强缓存如果命中,浏览器直接从自己的缓存中读取资源,不会发请求到服务器。比如某个css文件,如果浏览器在加载它所在的网页时,这个css文件的缓存配置命中了强缓存,浏览器就直接从缓存中加载这个css,连请求都不会发送到网页所在服务器;
2)当强缓存没有命中的时候,浏览器一定会发送一个请求到服务器,通过服务器端依据资源的另外一些http header验证这个资源是否命中协商缓存,如果协商缓存命中,服务器会将这个请求返回,但是不会返回这个资源的数据,而是告诉客户端可以直接从缓存中加载这个资源,于是浏览器就又会从自己的缓存中去加载这个资源;
3)强缓存与协商缓存的共同点是:如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;区别是:强缓存不发请求到服务器,协商缓存会发请求到服务器。
4)当协商缓存也没有命中的时候,浏览器直接从服务器加载资源数据。
强缓存是利用Expires或者Cache-Control这两个http response header实现的,它们都用来表示资源在客户端缓存的有效期。
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
浏览器行为对缓存的影响
如果资源已经被浏览器缓存下来,在缓存失效之前,再次请求时,默认会先检查是否命中强缓存,如果强缓存命中则直接读取缓存,如果强缓存没有命中则发请求到服务器检查是否命中协商缓存,如果协商缓存命中,则告诉浏览器还是可以从缓存读取,否则才从服务器返回最新的资源。这是默认的处理方式,这个方式可能被浏览器的行为改变:
1)当ctrl+f5强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存;
2)当f5刷新网页时,跳过强缓存,但是会检查协商缓存;