
函数(二)
函数是Python内建支持的一种封装,我们通过把大段的代码拆成函数,然后通过函数调用,就可以把复杂任务分解成一个个简单的任务,这种分解可以称之为面向过程的程序设计。 举个例子:比如你要熟练掌握Python,这是你的目标,如果当做一个任务,那这个任务会很复杂,因为你首先要懂Python的基础语法,数据类型、函数、对象等;其次你还要知道不少内建包和常用工具包的使用;再然后呢,你可能还需要懂一些网络编程,数据库开发;如果做web开发的话,还要学习web框架,以及运维相关的知识。
而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
高阶函数
变量可以指向函数。我们以Python内置的求绝对值的函数abs为例:
print(abs(-10)) # abs(-10)是函数调用
print(abs) # abs是函数本身
f = abs
print(f) # 函数本身也可以赋值给变量
print(f(-10)) # 直接调用abs()函数和调用变量f()完全相同
结论:函数本身也可以赋值给变量,即:变量可以指向函数。
函数名也是变量。那么函数名是什么呢?函数名其实就是指向函数的变量!对于abs()这个函数,完全可以把函数名abs看成变量,它指向一个可以计算绝对值的函数!
abs = 10
print(abs(-10))
把abs指向10后,就无法通过abs(-10)调用该函数了!因为abs这个变量已经不指向求绝对值函数而是指向一个整数10!当然实际代码绝对不能这么写,这里是为了说明函数名也是变量。要恢复abs函数,请重启Python交互环境。注:由于abs函数实际上是定义在import builtins模块中的,所以要让修改abs变量的指向在其它模块也生效,要用import builtins; builtins.abs = 10
既然变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。函数式编程就是指这种高度抽象的编程范式。
def add(x, y, f):
return f(x) + f(y)
MapReduce是Google提出的一个软件架构,用于处理大规模海量数据。并在之后广泛的应用于Google的各项应用中,2006年Apache的Hadoop项目正式将MapReduce纳入到项目中。
不过接下来我们要学习的是Python函数式编程中常用的内建函数map()和reduce()函数,而不是Google的MapReduce。
map
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
当Iterable只有一个时,将函数作用于这个Iterable的每个元素上,得到一个新的Iterator。我们看下面一张图就可以直观的说明map是如何工作的:
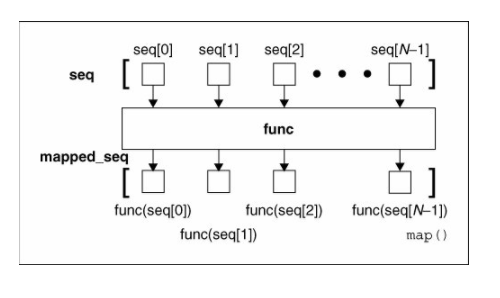
举个例子,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(r))
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,因此通过list()函数让它把整个序列都计算出来并返回一个list。
当Iterable有多个时,map()会并行地对每个Iterable执行如下过程:
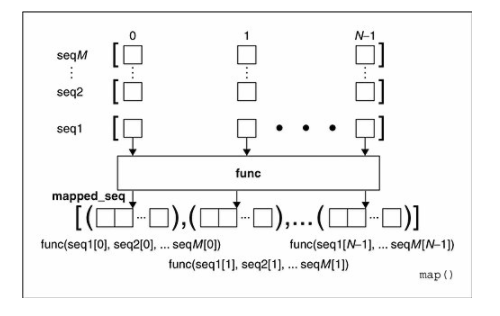
也就是说,每一个Iterable同一位置的元素在执行过一个多元函数之后,得到一个返回值,这些返回值放在一个结果列表中。
还是刚才那个例子,只不过我们拆分成三个序列,然后使用map进行计算:
def f(x,y,z):
return x * y * z
r = map(f, [1, 2, 3],[4, 5, 6],[ 7, 8, 9])
print(list(r)) # [28, 80, 162]
上面是返回值是一个值的情况,实际上也可以是一个元组。我们改一改刚才的例子:
def f(x,y,z):
return x * y * z, x+y+z
r = map(f, [1, 2, 3],[4, 5, 6],[ 7, 8, 9])
print(list(r)) # [(28, 12), (80, 15), (162, 18)]
好了,看例子很明白了吧。但是会不会有这样的问题,如果传入的Iterable长度不一样怎么办呢?使用多个迭代器时,当最短迭代器耗尽时,迭代器停止。
def f(x,y,z):
return x * y * z, x+y+z
r = map(f, [1, 2, 3, 4],[4, 5, 6,7],[ 7, 8, 9])
print(list(r)) # [(28, 12), (80, 15), (162, 18)]
嗯,结果跟上一个一样。
reduce
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的函数。请注意,在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
举个例子,比方说对一个序列求和,就可以用reduce实现:
from functools import reduce
def add(x, y):
return x + y
reduce(add, [1, 3, 5, 7, 9])
请注意啊,Python3里面使用reduce需要添加from functools import reduce,原因是reduce在_functools模块里面,而前面讲到map则在builtins,在builtins里面是不需要显示引入的。但是他们都属于built-ins的函数。
结合map函数,我们可以写一个字符串转数字的函数:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如:在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
newlist = list(filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
print(newlist)
比如:把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
newlist = list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
print(newlist)
过滤出1~100中平方根是整数的数:
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
newlist = list(filter(is_sqr, range(1, 101)))
print(newlist)
sort
Python内置的sorted()函数能够进行排序。
s = sorted([2, 11, -23, -9, 51])
print(s)
sorted()是一个高阶函数,接受一个key函数来实现自定义的排序,例如按绝对值大小排序:
s = sorted([2, 11, -23, -9, 51], key=abs)
print(s)
对字符串进行排序:
s = sorted(['Yisa','tom','Joe'], keys = str.lower)
print(s)
sorted()的可以传入参数:reverse=True 取反向排序
s = sorted(['Yisa','tom','Joe'], keys = str.lower, reverse=True)
print(s)
返回函数
函数可以作为值返回。高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
我们来实现一个可变参数的求和。通常情况下,求和的函数是这样定义的:
def calc_sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax
但是如果我不需要立刻就求和然后返回值,而是等我需要的时候在计算,怎么办呢?我们可以返回一个函数:
def wait_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
当我们调用wait_sum()时,返回的并不是求和结果,而是求和函数:
f = wait_sum(8,2,3,5)
print(f)
调用函数f时,才真正计算求和的结果:
print(f())
我们在函数wait_sum中又定义了函数sum,并且内部函数sum可以引用外部函数wait_sum的参数和局部变量,当调用wait_sum()返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
f1 = wait_sum(1, 3, 5, 7, 9)
f2 = wait_sum(1, 3, 5, 7, 9)
print(f1==f2)
闭包
定义:如果内部函数引用外部函数的参数和局部变量,并且内部函数被返回的这种结构就称为闭包。
注意到返回的函数在其定义内部引用了局部变量,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。我们来看一个例子:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
如果调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:
print(f1())
print(f2())
print(f3())
居然都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
如果想避免这种情况:返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量!!!